Next: Acoustic Signal Enhancement Up: Speaker Diarization: from Broadcast Previous: Summary of Differences and Contents
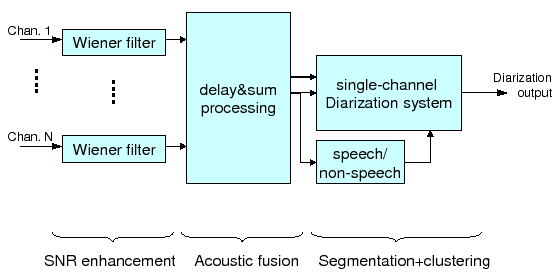
The proposed speaker diarization system for meetings can be broken up into three/four main blocks, as shown in figure 3.5. These are the single channel Signal-to-Noise Ratio (SNR) enhancement block, the multi-channel acoustic fusion and the segmentation and clustering system, which itself could be broken up into the speech/non-speech detection and the single-channel speaker diarization system.
When only one channel is to be processed, the acoustic fusion block is bypassed and the individual, SNR enhanced, signal is processed directly by the segmentation and clustering blocks. The advantage of this architecture is obvious, there is no need to generate a different system or techniques depending on the number of microphones available as both the acoustic fusion and the segmentation and clustering blocks accept an acoustic channel as an input and can be simply turned on/off depending on the characteristics of the data. The following sections describe each of the blocks in more detail.