Next: Frame-Level Cluster Purification Up: Acoustic Modeling Algorithms for Previous: Acoustic Modeling without Time Contents
Given the speaker clustering algorithm presented in this thesis, there are usually acoustic frames assigned to a cluster which do not belong to the modeled speaker. These frames are either non-speech or frames from another speaker. In this thesis this phenomenon is referred as cluster ``impurity''. It is very important to ensure that the clusters only contain one speaker and therefore the merging decision and stoping point criterion don't suffer from cluster impurity. Such cluster impurity has been studied separating it into two levels of detail (relative to two sources of error) and two algorithms are presented to detect and purify the clusters.
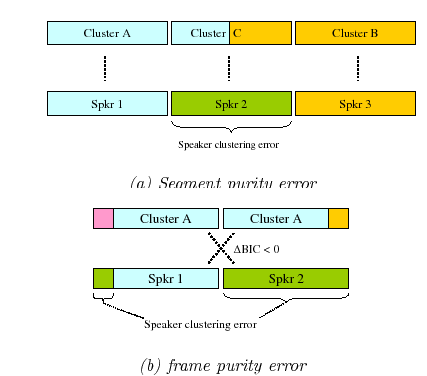
One source of error occurs when a cluster is created from speech segments from multiple speakers. In standard agglomerative systems there is no mechanism to split a cluster when segments from different speakers are assigned to the same cluster. This effect causes an increase in the final speaker error as seen in the example in Figure 4.8(a) for the case of two misplaced segments of two existing speakers. It is very possible that the speaker model for the mixed cluster is able to represent both speakers' data and therefore Viterbi segmentation does not achieve to homogenize the cluster classifying the acoustic frames into their respective clusters. At the end of the processing, the mixed cluster is likely to be assigned to an non existent speaker (or to either of the speaker present in it), causing a large increase on the Diarization Error Rate (DER).
The second source of error comes from the interference of
non-speech frames in both clusters during cluster comparison. This
is particularly true for short silences and short acoustic events
that belong to the modeled speaker but do not discriminate one
speaker from another. This can affect the final clustering in two
ways, as seen in Figure 4.8(b). First, when
comparing two clusters belonging to the same speaker, the
confounding frames can cause ![]() BIC to decide to keep them
separate. Second, false alarm errors are produced when non-speech
frames are assigned to one of the speakers.
BIC to decide to keep them
separate. Second, false alarm errors are produced when non-speech
frames are assigned to one of the speakers.
Both sources of error are interrelated and are caused by frames that are assigned to the wrong acoustic model. The difference is the unit that is considered is miss-assigned (segment or frame). In next subsections tho algorithms are proposed towards solving both problems. The first algorithm identifies the segments that acoustically deviate most from their cluster, and splits them into a new cluster. This is referred to as ``segment-level'' purification. The second algorithm locates the individual frames within a cluster than can cause problems in the merging state and avoids using them when computing the distance between the cluster pair. It is referred to as ``frame-level'' purification.