Next: Meetings Domain Overlap Regions Up: Input Data Analysis: Broadcast Previous: Average Number of Speakers Contents
Given the HMM acoustic modeling presented in the previous section, a minimum duration is applied to the segment length when performing the acoustic decoding of the data using the Viterbi algorithm. Such segments constitute the speaker turns and therefore it is important to analyze how long in average these are in the different subdomains, in order to adapt (if necessary) this parameter of the system to allow for smaller/larger turns.
In Table 3.12 the average, maximum and standard deviation of the speaker turn duration is given both for conference room meetings data and for the lecture room data. In the case of the conference room data, both the manual transcriptions and the forced-alignments are analyzed. When analyzing this property, two speaker turns from the same speaker but separated with a silence are considered different turns, and their durations counted separately.
It is clear that in the lecture room data the speaker turns are in average of much greater length, given that many times a lecturer speaker for elongated amounts of time. In some cases though it was seen that the transcriptions contained errors when small silence segments needed to be transcribed as such and were included within the speaker segment adjacent to it. The maximum speaker turn length for these is of 1:45 minutes approx.
On the conference room data there is a difference between the two transcriptions sources. This is mainly due to the discrepancies on the transcription of small silences. According to NIST rules for the evaluations, any silence segment of length greater than 0.3 seconds needs to be considered as such. This can be implemented efficiently in the forced-alignment transcriptions but it is more difficult to be followed by the human transcribers, leading to longer segments being annotated.
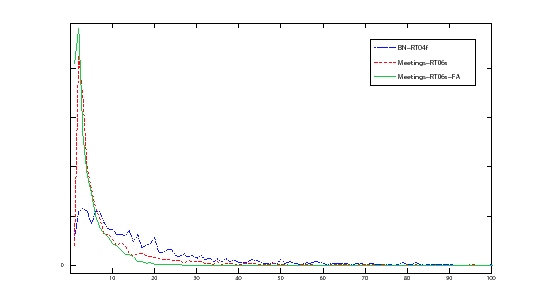
To further illustrate the distribution of the speaker turn durations, Figure 3.3 shows the histogram of all three analyzed cases, showing the durations histogram of the first 10s, with a resolution of 0.1 second. It can be observed that both transcriptions for the meetings conference room recordings have a similar shape, being very pointy around 0.3s, while the broadcast news shows reflect a broader shape. Such a small peak duration in the conference data has a reason to be in that overlap segmentes were also used when computing the speaker turn duration. These segments occur when two or more people are speaking at the same time and can just refer to people uttering affirmative/negative responses or short sentences.
In overall, the speaker turn length of meetings is much smaller than the average in broadcast news, which is modeled by the system with a minimum duration of 3 seconds. Such duration would be enough if the meetings system was evaluated using the hand-alignments, but needs to be reduced when evaluated with forced-alignments.
user 2008-12-08