Next: Friends-and-Enemies Clusters Initialization Up: Individual Algorithms Performance Previous: Number of Initial Clusters Contents
As seen in the previous section, it makes a big difference in the speaker diarization system the correct training of the speaker models. the EM-ML algorithm is appropriate for such endeavor, but in defining the number of iterations it normally undertrains or overfits to the training data. To solve this problem, the Cross-Validation EM (CV-EM) algorithm does EM training iterations over a set of parallel models that allow for a robust validation set to determine when to stop training (defined when the total likelihood of the validation set between two iterations increases less than 0.1%).
When using the CV-EM algorithm initial models use in average more EM iterations than the 5 iterations that were set for the standard EM-ML system. Once the models are retrained using almost the same data as in previous iterations, the CV-EM algorithm stops at 1 or 2 iterations, while the standard EM keeps doing 5 iterations. This reduced in average the computation of the system. the use of multiple parallel models in the CV-EM algorithm does not pose a computational burden as the increase in computation is minimal, which comes from the multiple accumulation of statistics for each model.
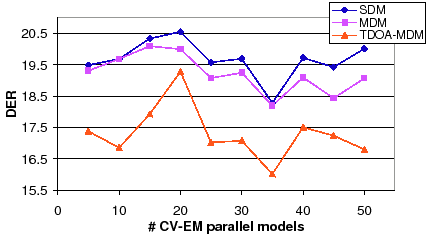
In the proposed CV-EM algorithm the number of parallel models used needs to be defined a priory. Figure 6.10 shows the evolution of the DER for the three considered systems by modifying the number of parallel models used in the algorithm. In the three cases the minimum DER value is found at 35 parallel models. At this optimum value, the CV-EM training obtains a 17.50% DER, a 6.46% relative improvement over the baseline.
user 2008-12-08